
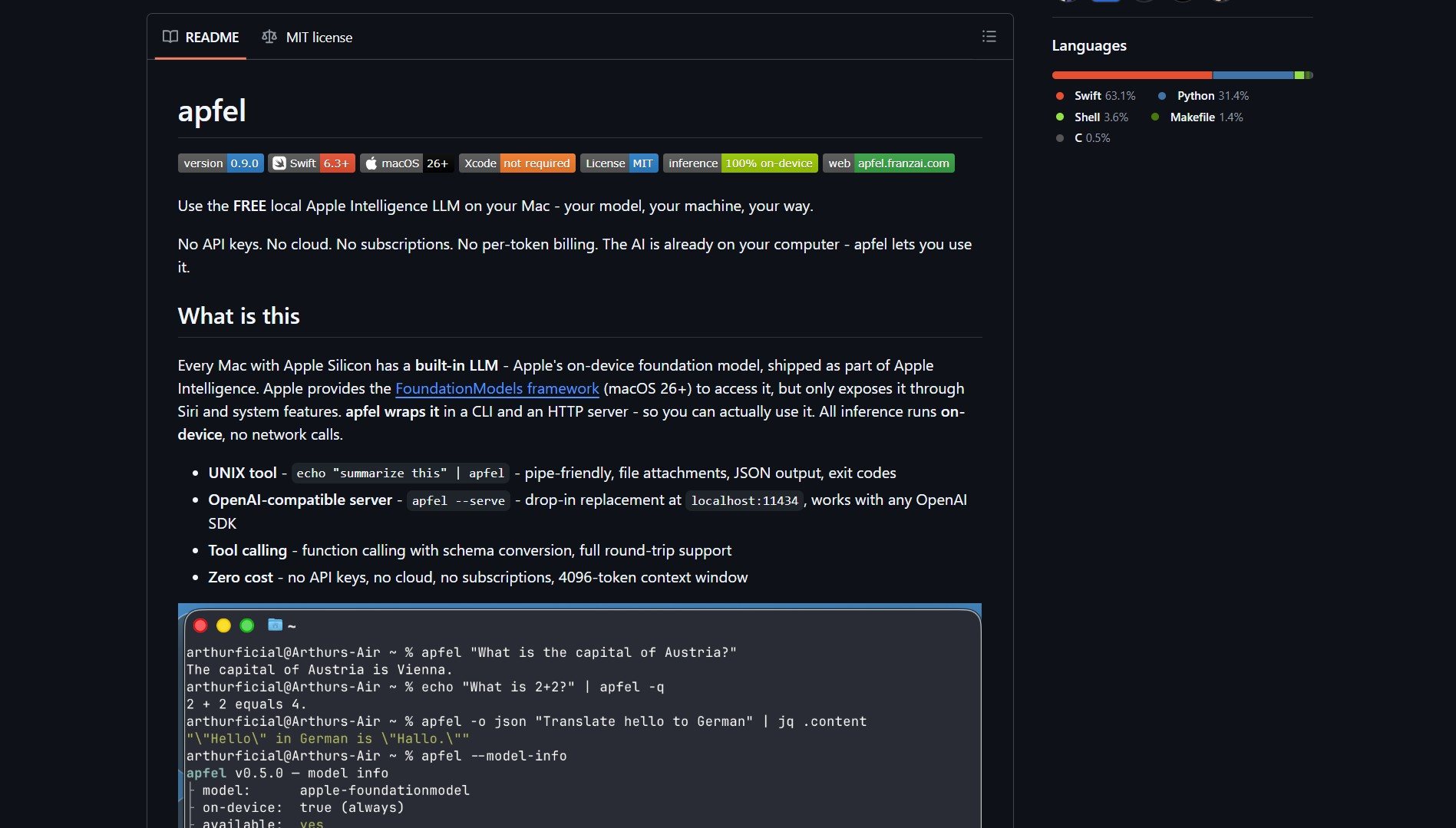
I ran into Apfel while browsing for local AI solutions, and what caught my attention was its premise: your Apple Silicon Mac already has a 3‑billion parameter language model sitting on disk, locked behind Siri. Apfel by Arthur‑Ficia is the key that unlocks it. It’s a native Swift project that wraps Apple’s on‑device Foundation Model into a CLI tool and an OpenAI‑compatible HTTP server. No API keys, no cloud, no per‑token costs. It runs entirely on your Neural Engine. As the project tagline puts it, “You already own the hardware. This is just the key.”
 Apfel GitHub repository homepage
Apfel GitHub repository homepage
What Is Apfel?
Apfel is for Apple Silicon Mac users, especially developers, who want to run a local AI model without APIs or cloud dependencies. It solves the problem of being tied to paid, internet‑based AI services by giving you direct access to the hardware‑accelerated model that’s already installed on your machine.
The project exposes two primary interfaces:
- CLI Tool – Run the model directly from your terminal for quick queries and script integration.
- OpenAI‑compatible HTTP Server – Spin up a local server that mimics the OpenAI API, allowing you to use existing tools and libraries that talk to OpenAI endpoints, but with zero network latency and no usage costs.
Because it uses Apple’s own Foundation Model, inference happens entirely on the Neural Engine, keeping everything on‑device and private.
Technical Details & Community Feedback
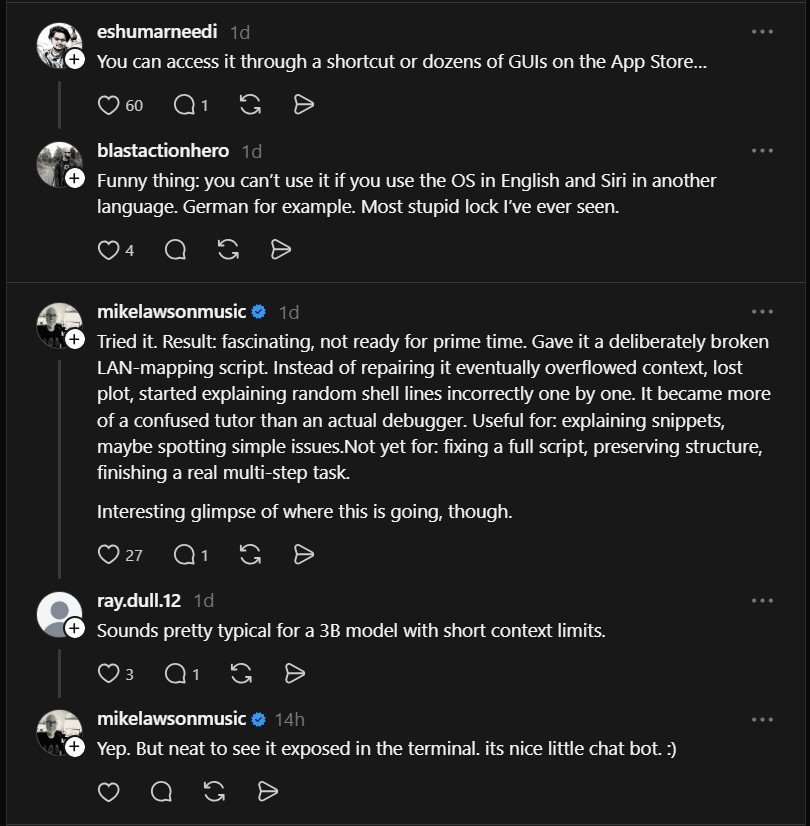
The model is a 3B parameter LLM, but there are important caveats around quantization and tuning that affect its practical performance.
“It’s a 3B, but quantized at 3‑bit (allegedly) uniformly, which neuters its stability, predictably, and accuracy (where applicable) by quite a bit. At a minimum, you want LLMs to be quantized to 4‑bits with some more important weights at higher bits (i.e. Q4_K_XL on HuggingFace). Furthermore, it seems like Apple’s own LLM model hasn’t been fine tuned or retrained for quite a while, so your mileage may vary a lot compared to newer releases like Google’s Gemma 4 1B/2B/4B models.”
— @lilwingflyhigh
 Community discussion about Apfel’s capabilities and limitations
Community discussion about Apfel’s capabilities and limitations
Current Use Cases & Limitations
Based on early user reports, Apfel is best suited for:
- Explaining code snippets – Getting plain‑English breakdowns of short scripts.
- Spotting simple issues – Identifying obvious syntax or logic errors.
- Educational / tutoring scenarios – Step‑by‑step explanations of shell commands or basic programming constructs.
It struggles with:
- Fixing full scripts – Loses context and structure when given larger files.
- Multi‑step debugging – Can’t maintain a coherent debugging session across many lines.
- Production‑grade code generation – Not yet reliable for real‑world development tasks.
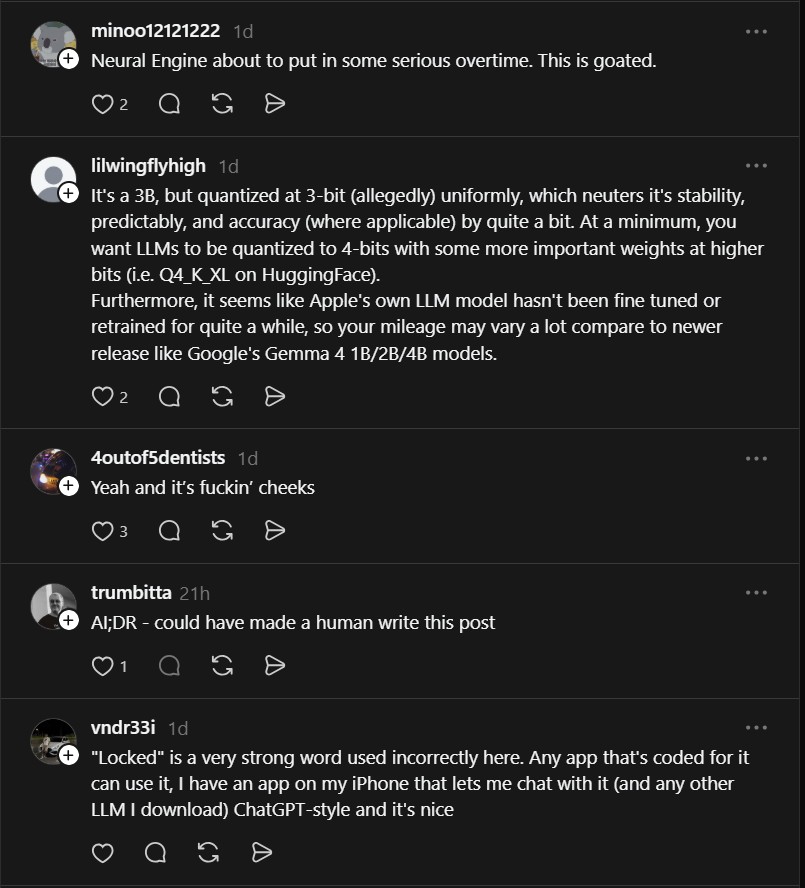
One hands‑on review noted:
“Tried it. Result: fascinating, not ready for prime time. Gave it a deliberately broken LAN‑mapping script. Instead of repairing it eventually overflowed context, lost plot, started explaining random shell lines incorrectly one by one. It became more of a confused tutor than an actual debugger. Useful for: explaining snippets, maybe spotting simple issues. Not yet for: fixing a full script, preserving structure, finishing a real multi‑step task. Interesting glimpse of where this is going, though.”
— @mikelawsonmusic
 More Threads commentary on Apfel’s current practical utility
More Threads commentary on Apfel’s current practical utility
Getting Started
If you have an Apple Silicon Mac and want to experiment with on‑device AI, Apfel is a straightforward way to get started. The project is open‑source and available on GitHub.
- Project link: https://github.com/Arthur-Ficial/apfel
Installation is via Homebrew or by building from source. Once installed, you can either run the CLI or start the HTTP server and point your existing OpenAI‑compatible tools to http://localhost:8080.
While Apfel isn’t yet a drop‑in replacement for cloud‑based models like GPT‑4, it represents an important step toward truly local, private AI inference. For developers curious about what their Mac’s Neural Engine can already do, it’s a fascinating, and free, window into the future of edge AI.
Developer Stack: If Apfel is too limited and you need more raw power on your Mac, Flash-moe lets you stream 397B MoE models directly from your SSD. If you just want a dead-simple desktop assistant without messing with Docker, Skales is the move.