
What made me stop scrolling: flash‑moe runs a 400‑billion parameter model on a MacBook Pro by streaming weights from SSD, turning a server‑rack problem into a local one. Built by danveloper in 24 hours with Claude Code autonomously running experiments, this pure C/Metal inference engine runs Qwen3.5‑397B‑A17B (a 397 billion parameter Mixture‑of‑Experts model) on a MacBook Pro with 48GB RAM at 4.4+ tokens/second with production‑quality output including tool calling.
 Flash‑moe GitHub repository homepage
Flash‑moe GitHub repository homepage
Flash‑moe by danveloper is for AI engineers who want to run massive models locally on consumer hardware, solving the problem of extreme memory requirements by streaming model weights from SSD instead of loading them into RAM. The entire 209GB model streams from SSD through a custom Metal compute pipeline. No Python, no frameworks, just C, Objective‑C, and hand‑tuned Metal shaders.
What Is Flash‑moe?
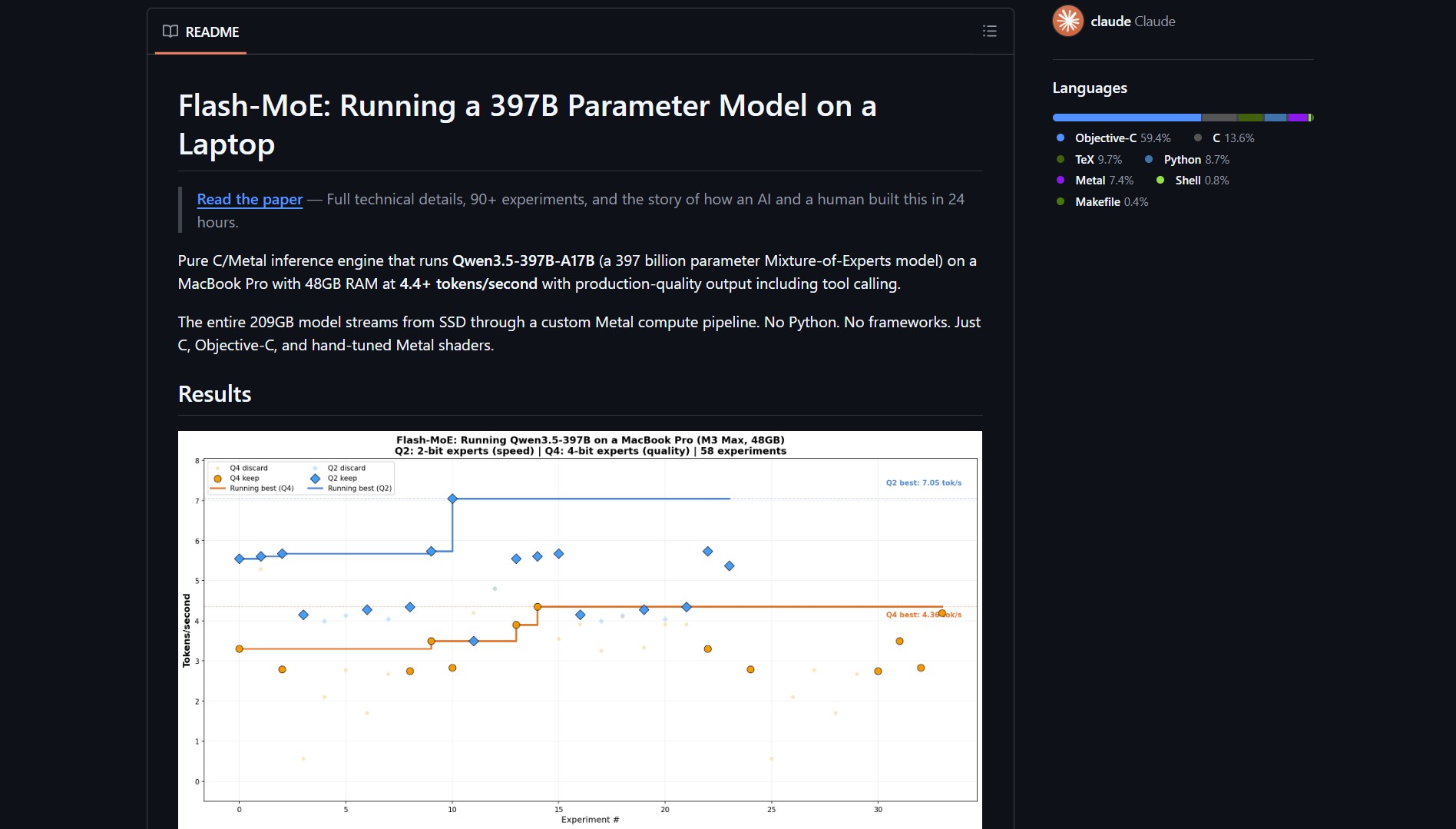
Flash‑moe is a pure C/Metal inference engine that runs Qwen3.5‑397B‑A17B, a 397 billion parameter Mixture‑of‑Experts (MoE) model, on a MacBook Pro with 48GB RAM at 4.4+ tokens/second. Instead of loading a 209GB model into memory, it streams weights from SSD to GPU on demand, pulling around five tokens per second on consumer hardware.
[!NOTE] The whole engine was built in 24 hours, with Claude Code autonomously running experiments based on an Apple research paper. This showcases how AI‑assisted development can rapidly produce high‑performance, low‑level systems.
How Flash‑moe Works: SSD Streaming & Metal Pipeline
| Component | Specification |
|---|---|
| Machine | MacBook Pro, Apple M3 Max |
| Chip | 16‑core CPU (12P + 4E), 40‑core GPU, 16‑core ANE |
| Memory | 48 GB unified (~400 GB/s bandwidth) |
| SSD | 1TB Apple Fabric, 17.5 GB/s sequential read (measured) |
| macOS | 26.2 (Darwin 25.2.0) |
| Model | Qwen3.5‑397B‑A17B (397B parameters, 209GB on disk) |
| Throughput | 4.4+ tokens/second with production‑quality output |
| Stack | Pure C, Objective‑C, hand‑tuned Metal shaders |
Key Technical Insights
- Memory Hierarchy Exploitation: Instead of holding all MoE layers in RAM, flash‑moe swaps them in and out from disk, leveraging fast SSD bandwidth.
- Active Parameters: Only 17B parameters are active at any time (typical for MoE models), making the streaming approach feasible.
- Metal Compute Pipeline: Custom shaders maximize GPU utilization while minimizing CPU‑GPU data transfer overhead.
- No Framework Overhead: By avoiding Python and high‑level frameworks, the engine reduces latency and memory footprint.
 Community discussions about flash‑moe’s technical approach
Community discussions about flash‑moe’s technical approach
Community Reactions & Technical Insights
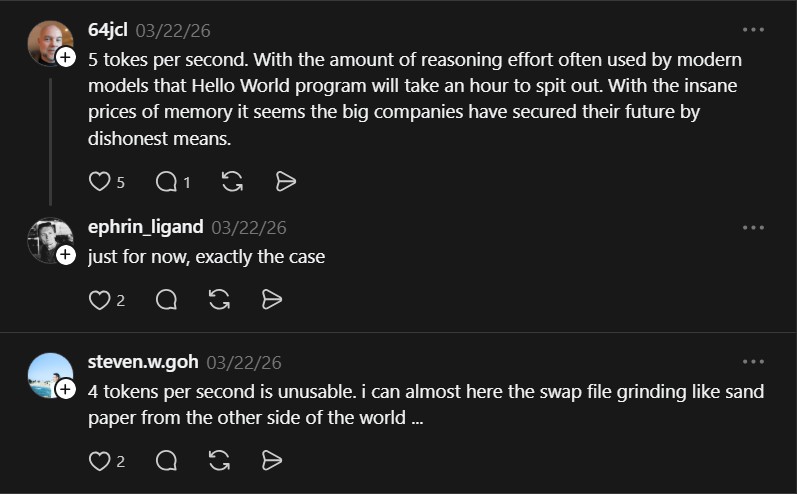
“5 tokes per second. With the amount of reasoning effort often used by modern models that Hello World program will take an hour to spit out. With the insane prices of memory it seems the big companies have secured their future by dishonest means.” , @64jcl
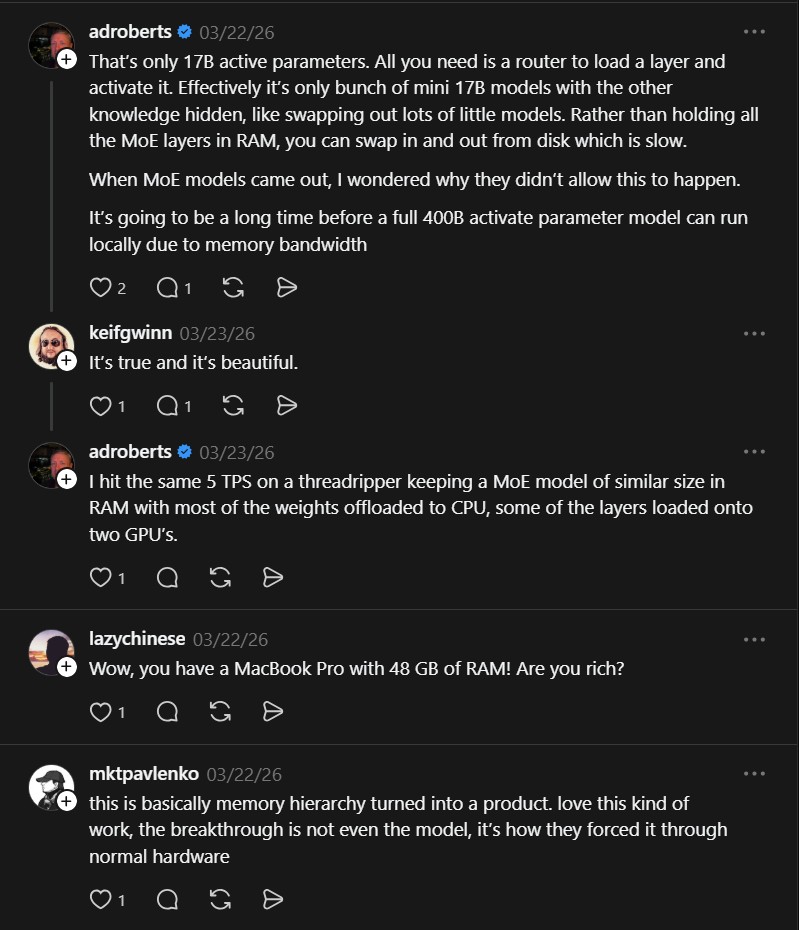
“That’s only 17B active parameters. All you need is a router to load a layer and activate it. Effectively it’s only bunch of mini 17B models with the other knowledge hidden, like swapping out lots of little models. Rather than holding all the MoE layers in RAM, you can swap in and out from disk which is slow. When MoE models came out, I wondered why they didn’t allow this to happen. It’s going to be a long time before a full 400B activate parameter model can run locally due to memory bandwidth” , @adroberts
“this is basically memory hierarchy turned into a product. love this kind of work, the breakthrough is not even the model, it’s how they forced it through normal hardware” , @mktpavlenko
 Further technical analysis from the developer community
Further technical analysis from the developer community
Why This Changes Local AI
Flash‑moe demonstrates that massive models can run on consumer hardware by rethinking the memory hierarchy. Here’s what that unlocks:
- Democratization of Large Models: Researchers and developers without server racks can experiment with 400B‑parameter models.
- Cost‑effective Inference: Avoids expensive GPU cloud costs for certain use cases.
- Hardware‑aware Optimization: Shows how deep understanding of Apple Silicon (unified memory, SSD bandwidth) can yield order‑of‑magnitude improvements.
- Rapid Prototyping: 24‑hour development cycle proves how AI‑assisted coding can accelerate low‑level systems work.
Local Alternatives: If you don’t need a massive MoE and just want the basic 3B model already on your Mac, Apfel is way easier to set up. On the experimental end, CL1 LLM Encoder is doing some wild stuff with biological neurons influencing token generation.
Project Link
Flash‑moe is more than an inference engine, it’s a proof‑of‑concept that changes the economics of local AI. By streaming weights from SSD instead of cramming them into RAM, it turns a MacBook Pro into a viable platform for billion‑parameter models, opening up new possibilities for on‑device AI that don’t require data‑center‑scale hardware.